(博客很久没更新了…坑爹的作业…) 本来我这篇博客准备写C++里面有关线程安全的,但是我最近看了一c++0x的一些新的标准和函数使用,感觉有必要提前拿出来分享一下。
CAS
说到CAS,我觉得学习C/C++的人应该不会不会陌生,CAS即为compare&swap,我将它理解为 先比较,后交换 。其实要理解它很容易,拿段代码看看
int compare_and_swap(int* reg, int old_value, int new_value) {
int old_reg_value = *reg;
if (old_reg_value == old_value)
*reg = new_value;
return old_reg_value;
}
上面的代码不知道大家看懂了没有,其实很简单,指针reg指向的值与old_value进行比较,如果是相同的,那么就将new_value赋给reg指向的对象。这个就是一个用C语言描述的CAS简单的实现。为了更好地放在情境中理解,我们可以实现函数返回值类型为bool的版本:
bool compare_and_swap (int *accum, int *dest, int newval) {
if ( *accum == *dest ) {
*dest = newval;
return true;
} else {
*accum = *dest;
return false;
}
}
我们将设现在有两个线程同时要对a进行操作,那么无论是哪个线程对a进行操作之前要检查自己“掌握”的a的信息与现在a的信息是否匹配,如果匹配,那么就对a进行操作,然后返回true,如果很可惜,在进行操作之前已经被别的线程抢先一步操作了,那么该线程保留的a的信息和a当前的信息不能匹配,那么就返回false。
目前,CAS的实现版本有多种,但是我这里只列出c++11中的CAS的实现版本,看代码~
template <class T>
bool atomic_exchange_weak( std::atomic<T>* obj,
T* excepted, T desired );
template <class T>
bool atomic_compare_exchange_weak( volatile std::atomic<T>* obj,
T* excepted, T desired );
template< class T >
bool atomic_compare_exchange_strong( std::atomic<T>* obj,
T* expected, T desired );
template< class T >
bool atomic_compare_exchange_strong( volatile std::atomic<T>* obj,
T* expected, T desired );
template< class T >
bool atomic_compare_exchange_weak_explicit( std::atomic<T>* obj,
T* expected, T desired,
std::memory_order succ,
std::memory_order fail );
template< class T >
bool atomic_compare_exchange_weak_explicit( volatile std::atomic<T>* obj,
T* expected, T desired,
std::memory_order succ,
std::memory_order fail );
template< class T >
bool atomic_compare_exchange_strong_explicit( std::atomic<T>* obj,
T* expected, T desired,
std::memory_order succ,
std::memory_order fail );
template< class T >
bool atomic_compare_exchange_strong_explicit( volatile std::atomic<T>* obj,
T* expected, T desired,
std::memory_order succ,
std::memory_order fail );
上面统计一下共有8个函数,但是我们抛开重载不说,其实只有4个函数,std::atomic_compare_exchange_weak, std::atomic_compare_exchange_strong, atomic_compare_exchange_weak_explicit和atomic_compare_exchange_strong_explicit。其实我们看到除了参数不同之外,上面的函数可分为weak和strong两类,按照cppreference.com里面关于这两种函数的解释,值得我们玩味:The weak forms of the functions are allowed to fail spuriously, that is, act as if obj != expected even if they are equal. 。这个是上面的原话,这就牵涉到了CAS的实现上的一个叫ABA的问题。我们在下面的内容中将会详细介绍。上面除了weak和strong的区别之外,我们还看到了参数的不同,主要在与volatile关键字的使用和std::memory_order。我们简单解释一下这两个知识点。volatile关键字通常是用来阻止(伪)编译器对那些它认为变量的值不能被代码本身改变的代码上执行任何优化。在C++中,一个被定义为vplatile的变量是为了显式说明这个变量可能在意想不到的情况下被改变,所以编译器不必去假设这个变量的值。优化器在用到这个变量时都必须重新读取这个变量的值而不是使用保存在寄存器的备份。在C/C++中,volatile关键字的作用有:
- 允许访问内存映射设备
- 允许在setjmp和longjmp之间使用变量
- 允许在信号处理函数中使用sig_atomic_t变量
接下来有个例子比较好地说明volatile变量的特性
int square(volatile int* ptr) {
return *ptr * *ptr;
}
这段代码的本意是要计算ptr所指向值的平方值,很可惜,并不是每次都能得到期望的结果,因为ptr所指向的参数是被volatile修饰的,编译器就会产生如下代码:
int square(volatile int* ptr) {
int a, b;
a = *ptr;
b = *ptr;
return a * b;
}
现在明白了为什么我们会有可能得不到我们期望的值了吧?如果想每次都能得到期望的结果,那么原代码就需要进行一些改变~
int square(volatile int* ptr) {
int a;
a = *ptr;
return a * a;
}
好了,我们了解了volatie的用处之后,我们来插播一个关键点std::atomic。std::atomic是一个模板类,其中std::atomic是一个模板类型为T的原子对象中封装一个类型为T的值。原子类型对象的主要特点就是从不同的县城访问不会导致数据竞争。因此从不同线程访问某个原子对象是良性 (well-defined) 行为,而通常对于非原子类型而言,并发访问某个对象(如果不做任何同步操作)会导致未定义 (undifined) 行为发生。关于c++中的std::atomic以及相关的并发技术,我将在后续的博客中进行学习探索。
现在我们考虑一个问题就是std::memory_order,这个东西到底是个什么玩意儿?我们看一下它的具体的定义先~
enum memory_order {
memory_order_relaxed,
memory_order_consume,
memory_order_acquire,
memory_order_release,
memory_order_acq_rel,
memory_order_seq_cst
};
这样看来,memory_order就是一个枚举类型。memory_order_relaxed(不指定内存屏障,所以内存操作执行时可能是乱序的),memory_order_acquire(插入一个内存读屏障,保证之前的读操作先一步完成,清空cpu上的”invalidate queues”),memory_order_consume(和memory_order_consume差不多吧),memory_order_release(插入内存写屏障), memory_order_acq_rel(同时插入读写两个屏障),memory_order_seq_cst(和memory_order_acq_rel差不多)。以上的实现如果想要细究的话,就要了解内存屏障的知识了,这个就不在这篇博客里面说了,有兴趣就自行google。
根据上面对于CAS在C++11中的实现已经有了初步的认识了,现在将放入具体的代码情境中看看吧(这个代码是cppreference.com里的)
#include <atomic>
template<class T>
struct node {
T data;
node* next;
node(const T& data) : data(data), next(nullptr) {}
};
template <class T>
class stack {
std::atomic<node<T>*> head;
public:
void push(const T& data) {
node<T>* new_node = new node<T>(data);
new_node->next = head.load(std::memory_order_relaxed);
while (!std::atomic_compare_exchange_weak_explicit(
&head,
&new_node->next,
new_node,
std::memory_order_release,
std::memory_order_relaxed));
}
};
int main () {
stack<int> s;
s.push(1);
s.push(2);
s.push(3);
return 0;
}
上述的代码要实现的是一个简单的压栈问题,这里面,我们考虑到如果有多个线程同时压栈,那么就会产生这样的问题:A在不知道栈顶已经被改变了的情况下,仍然向原来的栈顶压栈,这样显然是有问题的。所以增加了一个Loop,先询问栈顶是否是本线程所“期望”的,如果是,那么就进行压栈,如果不是,继续询问…这样就可以基本上保证一点,那就是压栈线程安全的。
大家看到这里,如果有C++开发经验的可能会产生疑问,我们之前讨论的CAS的compare是进行指针地址的比较,那如果这个地址被重用了呢?这就要关注一个CAS一个非常重要的问题:ABA问题
ABA IN CAS
首先我来描述一下ABA问题。假设有两个线程p1, p2访问同一个变量v,当p1访问变量a的时候,读到v的值为A;此时线程p1被抢占了,p2继续执行,p2首先将v的值变为B,然后又将变量a从B转换为A。此时p1线程执行,它发现v的值还是A,所以认为v在前后没有发生变化,就继续执。这样看起来貌似没有什么问题,这样,我们看一下下面的这个例子 现在有有个用单向链表实现的一个stack,里面有两个元素 A,B,C,其中A是栈顶元素,如下图所示
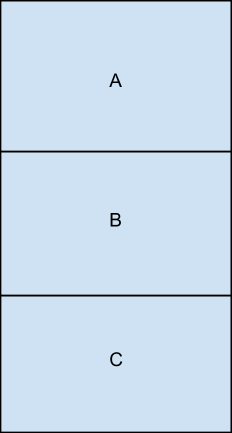
我们现在假设有两个进程p1, p2,其中p1需要将栈顶元素变为B,我们要执行的是
compare_and_set(stack_top,A, B);
但是很不幸,我们p1被p2抢占了,这个时候p2要做什么呢?p2要删除B(不要问我为什么,p2就是来捣蛋的,“不给糖就捣蛋~~”),等到p2结束的时候,我们看到现在A,B,C是这个状态:AC在栈中,B已经被删除了,如下图所示
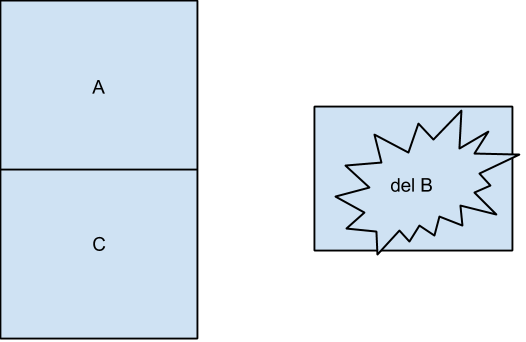
好了,现在到p1继续执行了,先比较栈顶元素是否是A,对了,是A,那么compare_and_set指令执行正确了。然后它将栈顶设为原栈顶元素的下一个元素(B),但是B已经被DELETE了,然后栈顶元素会被赋予一个自由的内存空间,因为这个空间是没有被定义的,所以程序很容易就crash了。
这里有一个非常经典的现实场景来说明这个问题:
你拿着一个装满钱的手提箱在飞机场,此时过来了一个火辣性感的美女,然后她很暖昧地挑逗着你,并趁你不注意的时候,把用一个一模一样的手提箱和你那装满钱的箱子调了个包,然后就离开了,你看到你的手提箱还在那,于是就提着手提箱去赶飞机去了。
好了,现在就需要来解决这个ABA问题了,该怎么解决呢?
Wikipedia上面提供了一个双保险的方法:使用double-CAS来解决这个问题,也就是在要比较的值后面家一个版本计数器,当进行比较的时候,只有两个部分都满足才能进行下一步的set的操作,set的时候不仅是要赋予新的值,后面的版本计数器要相应地增加1。这就意味着如果ABA情况发生,即使是操作的值是符合的,但是版本计数器却不相同,这样compare的过程就会不会返回正确的信息。